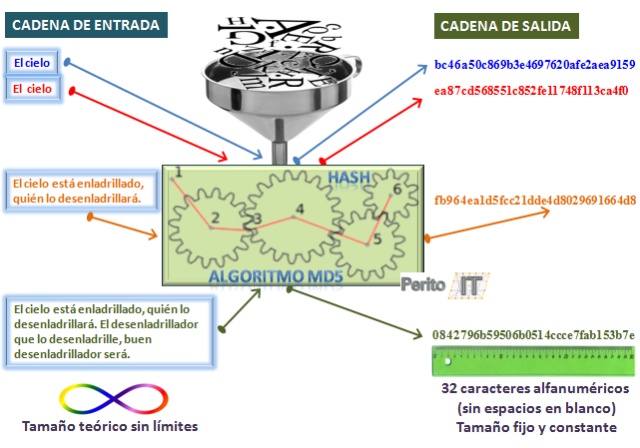
Los algoritmos hash o funciones de resumen son unos algoritmos de formulación matemática, los cuales, a partir de la consideración de elemento de entrada bien sea una cadena de caracteres, un fichero, una carpeta, una partición o un disco entero, son capaces de proporcionar a modo de «resumen» una salida de caracteres alfanuméricos de longitud fija, constante y estable para cada entrada.
Los algoritmos hash o funciones de resumen son unos algoritmos de formulación matemática, los cuales, a partir de la consideración de elemento de entrada bien sea una cadena de caracteres, un fichero, una carpeta, una partición o un disco entero, son capaces de proporcionar a modo de «resumen» una salida de caracteres alfanuméricos de longitud fija, constante y estable para cada entrada.
>> Ver «Los usos de los Algortimos Hash o Funciones Resumen»
Características principales de los Hash
Las características principales del proceso de cálculo de los algoritmos hash son los siguientes:
– La salida proporcionada es un valor unívoco para una entrada en concreto y, salvo la presencia excepcional de colisiones en algoritmos sencillos, en un mismo algoritmo, no es posible obtener dos salidas diferentes para una misma entrada, ni dos entradas diferentes pueden generar un mismo valor de salida.
– La salida proporcionada es de longitud fija y varía según el algoritmo aplicado, con independencia de la longitud, tamaño o contenido de la entrada.
– El cálculo realizado es un proceso de generación unidireccional e irreversible puesto que tomando una entrada y aplicando el algoritmo se obtiene siempre el mismo valor de salida, pero conociendo el valor la salida no se puede llevar a cabo el proceso inverso y llegar a conocer la entrada utilizada para la generación de dicha salida, salvo en cadenas muy pequeñas (de unos pocos caracteres y sin caracteres especiales) a las cuales se les podría aplicar «métodos de ataque de fuerza bruta«
– Cada algoritmo hash posee sus propias reglas de cálculo, son estables y universales para todos aquellos programas que utilicen el mismo algoritmo hash de cálculo, no existiendo dos formulaciones de algoritmos diferentes con el mismo nombre, por lo que un algoritmo siempre ofrece el mismo valor de salida para una entrada dada, con total independencia de la herramienta, software o dispositivo utilizado para su cálculo.
Algoritmo de codificación MD5 Web de cálculo MD5 para textos
Contextos habituales de utilización de los algoritmos hash
Estas características hacen que la utilización de algoritmos hash sea muy frecuente en la práctica de la informática forense en los siguientes contextos:
– La verificación de ficheros idénticos. Internamente dos ficheros son idénticos aunque cambien de nombre o de extensión incluso si se abren, siempre que no se grabe o acepte cambio alguno no cambia el contenido interno de los mismos, por lo tanto, a través del valor del algoritmo hash se puede conocer y corroborar si el contenido de dos ficheros es idéntico.
Dada esta propiedad, los algoritmos hash son utilizados en situaciones en las que es necesario o conveniente verificar esta identidad de contenido interno como, por ejemplo, cuando se aporta un fichero en una investigación forense, o cuando alguien se descarga un software o un fichero y se quiere comprobar que es idéntico al que los desarrolladores han liberado en origen, o quizás, para verificar si algún fichero de un Sistema o de un Aplicativo ha sido modificado por un malware introduciéndole una cadena de código malicioso.
– En la identificación y registro de copias forenses. En la realización de clones idénticos (imagen bit a bit) de discos HDD (Hard Drive Disk), es decir, los discos duros convencionales, pudiéndose aplicar el algoritmo a todo el disco, a particiones concretas o a carpetas determinadas o de forma individualizada a grupos de ficheros. Ésta es una comprobación muy significativa y relevante puesto que, si no se realizan manipulaciones (borrado, copiado de ficheros o modificación interna de los mismos), la información permanece estable y perenne sin alteración alguna, por lo que el valor del algoritmo hash permanecerá también invariable a lo largo del tiempo.
En este sentido, no se puede hacer la misma afirmación respecto a los discos SSD (Solid State Drive) cuando se pretende validar la imagen completa del disco, puesto que el mero hecho de conectarlos hace que la información interna del propio dispositivo varíe puesto que funcionan a modo de memoria flash y no son dispositivos de grabado en soporte físico como los discos tradicionales, consecuentemente, el valor del hash obtenido sobre el contenido global del disco será diferente cada ocasión en la que se calcule y obtenga.
En la investigación forense se utiliza el cálculo de los valores hash a nivel global o extendido en las carpetas sobre sus ficheros para poder comparar el contenido de dispositivos frente a otros dispositivos o las carpetas conteniendo ficheros incautados pero, tal y como se ha comentado, los valores hash de los ficheros examinados sólo serán idénticos si los ficheros comparados no han sido variados internamente, aunque hayan variado de nombre y de extensión, por lo que:
– A) En sentido positivo, la ventaja de investigar usando los algoritmos Hash: Si los ficheros que se copiaron no han sido modificados, el cálculo de los valores hash permite realizar una comparativa rápida, fiable e infalible, no dejando lugar a dudas de si el contenido de los ficheros examinados es el mismo, aunque exista cambio de nombre o de extensión del fichero, siempre y cuando no se abra y grabe. Este proceso se puede automatizar ejecutándose de forma rápida y con una gran economía de esfuerzo, recursos y tiempo.
– B) En sentido negativo, la desventaja o debilidad de investigar usando los algoritmos Hash: La posibilidad de que tras la copia o sustracción de los ficheros, estos hayan sido modificados para su uso o, simplemente, porque se haya añadido, modificado o quitado algo, por nimio que esto sea o represente, hará que se obtenga un valor hash diferente por lo que, bajo esta premisa, la comparativa a través del hash dará como resultado que se trata de ficheros diferentes.
Normalmente, en las investigaciones forenses, los Cuerpos y Fuerzas de Seguridad, cuando examinan la similitud del contenido de los dispositivos lo hacen en base a la comparativa de algoritmos hash, que es un método adecuado y razonable en cuanto a esfuerzo requerido en la investigación y, con el resultado de la comparativa de los valores hash de los ficheros contenidos en los dispositivos, se llega a la determinación de si se ha encontrado ficheros idénticos o no, con independencia del nombre que pudieran tener los ficheros.
Excepciones en el uso de los algoritmos Hash para la investigación
Sin embargo, en muchas investigaciones, como pudieran ser la sustracción de información empresarial, aunque la verificación de los hash sea la primera intervención lógica a llevar a cabo y el método adecuado en el primer nivel de intervención, finalmente, es necesario realizar una segunda intervención puesto que, en ocasiones, se posee la palmaria sospecha de que los ficheros han sido modificados para su uso como, por ejemplo, la introducción datos de la nueva empresa (un nombre, datos de contacto, NIF, color corporativo, etc), o un logo, o cambiando cualquiera de los elementos menores no significativos, pero manteniéndose aquella información básica que constituye la síntesis del conocimiento o del contenido del mismo y, es precisamente, este contenido originario el que puede evidenciar el origen común de ambos ficheros con un alto grado de similitud entre los mismos.
En estos casos, donde se sospecha que los ficheros sustraídos han podido ser modificados para su uso, la investigación por medio de algoritmos hash, tal y como se ha comentado, no es válida haciéndose necesario, en un segundo nivel de intervención, el examen individualizado de los ficheros, que por economía de esfuerzo se han de categorizar por tipología de ficheros y por similitud de tamaños de los mismos.
No obstante, dependiendo del volumen de información y del número de ficheros se puede llegar a convertir en una actividad faraónica que, normalmente, no es asumida por los Cuerpos y Fuerzas de Seguridad, por lo que sólo es asumida por encargos particulares de la parte que posee la sospecha de la manipulación/modificación posterior de los ficheros y que pueda ver infringidos sus derechos de titularidad/propiedad de los ficheros o información investigada que son los verdaderamente perjudicados en una investigación en base únicamente a los valores hash de los ficheros comparados pero el desconocimiento del funcionamiento de estos algoritmos hace que la parte afectada no conozca la existencia de esta otra posibilidad , por lo que el desconocimiento hace que la investigación no continúe profundizando en este sentido.
Algoritmos Hash utilizados en l a práctica común y habitual
Simplemente a modo de apunte, quisiera comentar que los algoritmos más comúnmente utilizados son el MD5, SHA1, SHA-256, aunque los profesionales y técnicos más ortodoxos descartan el MD5 porque ha presentado vulnerabilidades de colisiones y frente a los ataques de fuerza bruta (algoritmo roto en 2004), en 2015 ocurrió lo mismo con el algoritmo SHA-1.
No obstante, en mi opinión en la práctica del día a día esto no representa un problema significativo para su empleo en informática forense puesto que es un inconveniente menor y de una probabilidad remota frente a la ventaja de ser de los algoritmos más simple como el MD5 (de 128 bits) y, por ello, ser más rápido que el resto de algoritmos a la hora de calcular, característica ésta que lo hace más idóneo para grandes volúmenes de verificación de ficheros o de información que es la situación más habitual tal que podemos encontrar cuando se trabaja, por ejemplo, con discos duros incautados.